HSAC-LLM (Active request)
The Robot proactively sends voice avoidance requests after detecting collision risk.
Ask the pedestrian margin to his closer side.
The Robot proactively sends voice avoidance requests after detecting collision risk.
Ask the pedestrian margin to his closer side.
After receiving the pedestrian's state of his moving trajectory to the left side, the robot promptly shifts its position to the opposite side to avert a collision and responds with its next intended move.
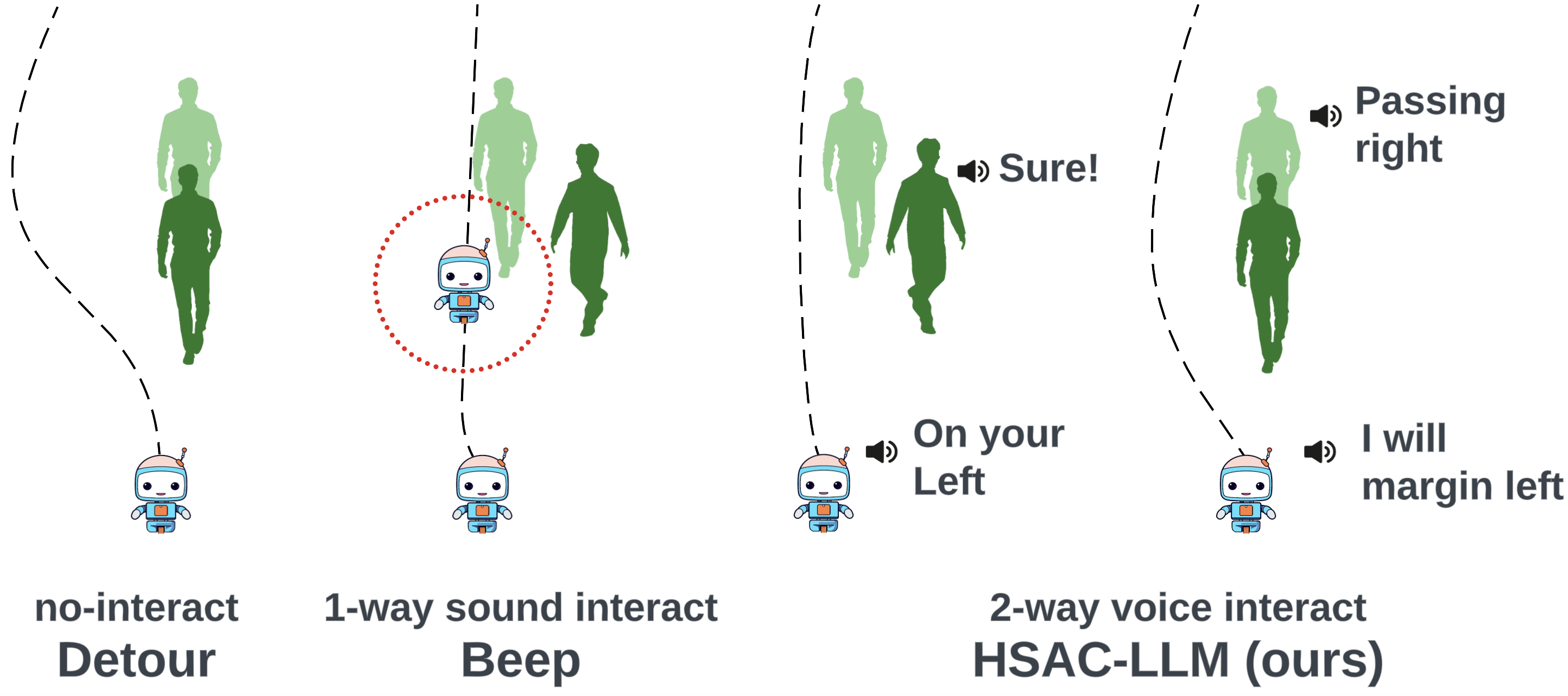
Robot navigation is crucial across various domains, yet traditional methods focus on efficiency and obstacle avoidance, often overlooking human behavior in shared spaces. With the rise of service robots, socially aware navigation has gained prominence. However, existing approaches primarily predict pedestrian movements or issue alerts, lacking true human-robot interaction. We introduce Hybrid Soft Actor-Critic with Large Language Model (HSAC-LLM), a novel framework for socially aware navigation. By integrating deep reinforcement learning with large language models, HSAC-LLM enables bidirectional natural language interactions, predicting both continuous and discrete navigation actions. When potential collisions arise, the robot proactively communicates with pedestrians to determine avoidance strategies. Experiments in 2D simulation, Gazebo, and real-world environments demonstrate that HSAC-LLM outperforms state-of-the-art DRL methods in interaction, navigation, and obstacle avoidance. This paradigm advances effective human-robot interactions in dynamic settings.
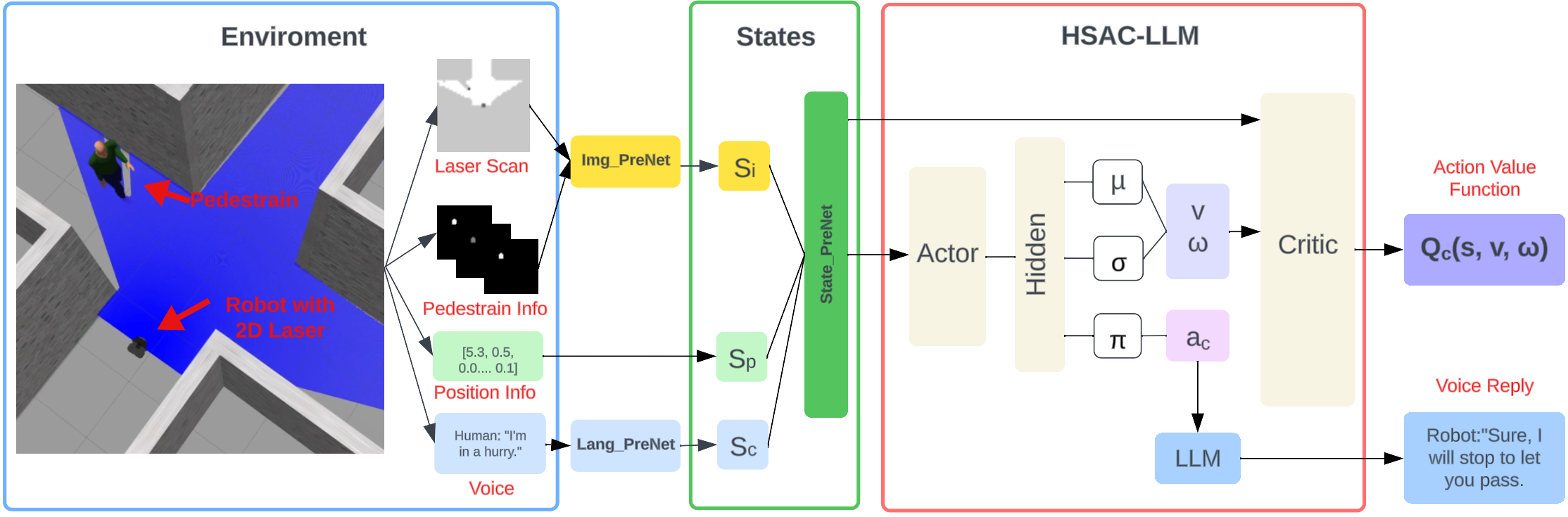
Raw observations like radar scans, pedestrian position, and speed information from the environment will be processed by Img_PreNet built by convolutional and fully connected layers. Pedestrian's vocal messages will be handled by Lang_PreNet built with LLM into action state vectors. Finally State_PreNet built by one fully connected layer will combine previously processed data with the robot's position info into a 512-dimensional vector state used for the HSAC-LLM algorithm.
The behavior of the robot involves both continuous and discrete elements. We categorize the robot’s motion controls, angular and linear velocities, as continuous actions, while post-interaction decisions are discrete actions. HSAC was used to model both continuous and discrete robot actions.

LLM was introduced to serve as a conduit between discrete action codes and intuitive voice messages. Through the presentation of prompts that encapsulate the contextual information and environment dynamics, coupled with dialogue examples, the LLM performs a two-way translation. This translation facilitates the transformation between action code and the respective voice messages from both pedestrians and the robot.
Proactive made by robot
Robot: "Could you move to your right please?"
Pedestrian: "Sure I will do that!"
Proactive made by pedestrian
Pedestrian: "On your left!"
Robot: "I will shift to my right."
Proactive made by pedestrian
Pedestrian: "Moving towards your right side!"
Robot: "I shift to the left then."
Proactive made by pedestrian
Pedestrian: "On your right!"
Robot: "I will move to my left."
Proactive made by robot
Robot: "Could you please stop so I can pass?"
Pedestrian: "Sure, go ahead!"
Proactive made by pedestrian
Pedestrian: "Could you let me pass first?"
Robot: "Of course, I will stop."
Proactive made by pedestrian
Pedestrian: "I am already late for my work!"
Robot: "Ok I will stop."
Proactive made by pedestrian
Pedestrian: "I am in a hurry!"
Robot: "Ok, I will stop to left you pass."
@article{wen2024socially,
title={Socially-Aware Robot Navigation Enhanced by Bidirectional Natural Language Conversations Using Large Language Models},
author={Wen, Congcong and Liu, Yifan and Bethala, Geeta Chandra Raju and Yuan, Shuaihang and Huang, Hao and Hao, Yu and Wang, Mengyu and Liu, Yu-Shen and Tzes, Anthony and Fang, Yi},
journal={arXiv preprint arXiv:2409.04965},
year={2024}
}